Based on this notebook by Rick Muller, licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
Note that the original notebook is much longer and more detailed.
1Python Overview¶
This is a quick introduction to Python. There are lots of other places to learn the language more thoroughly. I have collected a list of useful links, including ones to other learning resources, at the end of this notebook. If you want a little more depth, Python Tutorial is a great place to start, as is Zed Shaw’s Learn Python the Hard Way.
The lessons that follow make use of Jupyter notebooks. Briefly, notebooks have code cells (that are generally followed by result cells) and text cells. The text cells are the stuff that you’re reading now.
1.1What You Need to Install¶
These notes assume you have a Python distribution that includes:
Numpy, the core numerical extensions for linear algebra and multidimensional arrays;
Scipy, additional libraries for scientific programming;
Matplotlib, excellent plotting and graphing libraries;
Jupyter, with the additional libraries required for the notebook interface.
The easiest way to install and update all of these is using the Anaconda package, which contains everything you need for scientific programming.
1.2Using Python as a Calculator¶
Many of the things I used to use a calculator for, I now use Python for:
2 + 24(50 - 5 * 6) / 45.0Differently from C, in Python an integer division does what you would expect:
7 / 32.3333333333333335However, sometimes it can be useful to do a proper truncating divisions. In these cases you can use the // operator:
7 // 32Python libraries are called modules, and can be imported with an import statement. As an example, consider the math module, which is a standard module containing many useful mathematical functions and constants. We can either import the whole module or just the thing(s) we need:
import math
math.sqrt(81)9.0from math import sqrt
sqrt(81)9.0You can define variables using the equals (=) sign:
width = 20
length = 30
area = length * width
area600If you try to access a variable that you haven’t yet defined, you get an error:
volume---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[8], line 1
----> 1 volume
NameError: name 'volume' is not definedYou can name a variable almost anything you want. It needs to start with an alphabetical character or “_”, can contain alphanumeric characters plus underscores (“_”). Certain words, however, are reserved for the language:
and, as, assert, break, class, continue, def, del, elif, else, except,
exec, finally, for, from, global, if, import, in, is, lambda, not, or,
pass, print, raise, return, try, while, with, yieldTrying to define a variable using one of these will result in a syntax error:
return = 0 Cell In[9], line 1
return = 0
^
SyntaxError: invalid syntax
The Python Tutorial has more on using Python as an interactive shell.
1.3Strings¶
Strings are lists of printable characters, and can be defined using either single quotes
'Hello, World!''Hello, World!'or double quotes
"Hello, World!"'Hello, World!'But not both at the same time, unless you want one of the symbols to be part of the string.
"He's a Rebel""He's a Rebel"'She asked, "How are you today?"''She asked, "How are you today?"'Just like the other two data objects we’re familiar with (integer and floating numbers), you can assign a string to a variable
greeting = "Hello, World!"The print statement is often used for printing character strings:
print(greeting)Hello, World!
The print function can also print data types other than strings:
print("The area is", area)The area is 600
In the above snippet, the number 600 (stored in the variable “area”) is converted into a string before being printed out. Note that from Python 3.6, it is also possible to use f-strings, which are a convenient way to print variables:
print(f"The area is {area}")The area is 600
This syntax can be used to finely control the output:
print(f"The area is {area:.2f}")The area is 600.00
You can use the + operator to concatenate strings together:
statement = "Hello," + "World!"
print(statement)Hello,World!
Don’t forget the space between the strings, if you want one there.
statement = "Hello, " + "World!"
print(statement)Hello, World!
You can use + to concatenate multiple strings in a single statement:
print("This " + "is " + "a " + "longer " + "statement.")This is a longer statement.
or use commas:
print("This", "is", "a", "longer", "statement.")This is a longer statement.
If you have a lot of words to concatenate together, there are other, more efficient ways to do this. But this is fine for linking a few strings together.
1.4Lists¶
Very often in a programming language, one wants to keep a group of similar items together. Python does this using a data type called lists.
days_of_the_week = ["Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"]You can access members of the list using the index of that item:
days_of_the_week[2]'Tuesday'As in C, the index of the first element of a list is 0. Thus, in this example, the 0 element is “Sunday”, 1 is “Monday”, and so on.
Differently from C, If you need to access the n-th element from the end of the list, you can use a negative index. For example, the -1 element of a list is the last element:
days_of_the_week[-1]'Saturday'You can add additional items to the list using the .append() method:
languages = ["Fortran", "C", "C++"]
languages.append("Python")
print(languages)['Fortran', 'C', 'C++', 'Python']
The range() command is a convenient way to make sequences of numbers:
range(10)range(0, 10)To see the items in the range, you can make a list of it.
list(range(10))[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]Note that range(n) starts at 0 and gives the sequential list of integers less than n. If you want to start at a different number, use range(start, stop)
list(range(2,8))[2, 3, 4, 5, 6, 7]The lists created above with range have a step of 1 between elements. You can also give a fixed step size via a third command:
evens = range(0, 20, 2)
list(evens)[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]evens[3]6Lists do not have to hold the same data type. For example,
["Today", 7, 99.3, ""]['Today', 7, 99.3, '']You can find out how long a list is using the len() command:
len(evens)101.5Iteration, Indentation, and Blocks¶
One of the most useful things you can do with lists is to iterate through them, i.e. to go through each element one at a time. To do this in Python, we use the for statement:
for day in days_of_the_week:
print(day)Sunday
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
(Almost) every programming language defines blocks of code in some way. In C, one uses curly braces {} to define these blocks.
Python uses a colon, :, followed by indentation level to define code blocks. A block is made by consecutive lines that have the same indentation level. In the above example the block was only a single line, but we could have had longer blocks as well:
for day in days_of_the_week:
statement = "Today is " + day
print(statement)Today is Sunday
Today is Monday
Today is Tuesday
Today is Wednesday
Today is Thursday
Today is Friday
Today is Saturday
The range() command is particularly useful with the for statement to execute loops of a specified length:
for i in range(20):
print("The square of ", i, " is ", i * i)The square of 0 is 0
The square of 1 is 1
The square of 2 is 4
The square of 3 is 9
The square of 4 is 16
The square of 5 is 25
The square of 6 is 36
The square of 7 is 49
The square of 8 is 64
The square of 9 is 81
The square of 10 is 100
The square of 11 is 121
The square of 12 is 144
The square of 13 is 169
The square of 14 is 196
The square of 15 is 225
The square of 16 is 256
The square of 17 is 289
The square of 18 is 324
The square of 19 is 361
1.6Slicing¶
Strings are sequences of things, just like lists. Therefore, as with lists, you can iterate through the letters in a string:
for letter in "Sunday":
print(letter)S
u
n
d
a
y
This is only occasionally useful. Slightly more useful is the slicing operation, which you can also use on any sequence. We already know that we can use indexing to get the first element of a list:
days_of_the_week[0]'Sunday'By extending this notation, we can obtain subsequences. For instance, a sequence containing the first two elements of a list can be generated with
days_of_the_week[0:2]['Sunday', 'Monday']or simply
days_of_the_week[:2]['Sunday', 'Monday']If we want the last items of the list, we can do this with negative slicing:
days_of_the_week[-2:]['Friday', 'Saturday']which is somewhat logically consistent with negative indices accessing the last elements of the list.
You can do:
workdays = days_of_the_week[1:6]
workdays['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']The same technique can be applied to strings:
day = "Monday"
abbreviation = day[:3]
abbreviation'Mon'If we really want to get fancy, we can pass a third element into the slice, which specifies a step length (just like a third argument to the range() function specifies the step):
numbers = list(range(0, 40))
evens = numbers[2::2]
evens[2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38]Note that in this example the second argument was omitted, so that the slice started at 2, went to the end of the list, and took every second element, to generate the list of even numbers less that 40.
1.7Booleans and Truth Testing¶
Contrary to C, Python has builtin boolean variables, i.e. that can be either True or False, and can be used with if statements:
if day == "Sunday":
print("Sleep in")
else:
print("Go to work")Go to work
(note that the day variable was set in a previous cell). In Python, conditional expressions are also booleans. For instance:
day == "Sunday"FalseAs in C, the == operator performs equality testing. If the two items are equal, it returns True, otherwise it returns False. In this case, it is comparing two variables, the string "Sunday", and whatever is stored in the variable day, which, in this case, is the other string "Saturday". Since the two strings are not equal to each other, the truth test has the false value.
The if statement that contains the truth test is followed by a code block (a colon followed by an indented block of code). If the boolean is true, it executes the code in that block. Since it is false in the above example, we don’t see that code executed.
The first block of code is followed by an else statement, which is executed if nothing else in the above if statement is true. Since the value was false, this code is executed, which is why we see “Go to work”.
You can compare any data types in Python:
1 == 2False50 == 2*25True3 < 3.14159True1 == 1.0True1 != 0True1 <= 2True1 >= 1TrueWe see a few other boolean operators here, all of which which should be self-explanatory. Less than, equality, non-equality, and so on.
Particularly interesting is the 1 == 1.0 test, which is true, since even though the two objects are different data types (integer and floating point number), they have the same value.
We can do boolean tests on lists as well, although the behaviour is somehow counterintuitive: for equality, it works as you would expect, and the comparison is carried out element-wise:
[1, 2, 3] == [1, 2, 4]FalseFor inequalities, the comparison is still done element-wise, although the comparison result is determined by the comparison of the first unequal elements. Any other subsequent element does not affect the result.
[1, 2, 3, 10] < [1, 2, 4, 3]TrueFinally, note that you can also string multiple comparisons together, which can result in very intuitive tests:
hours = 5
0 < hours < 24TrueIf statements can have elif parts (which is a contraction of “else if”), in addition to if/else blocks. For example:
if day == "Sunday":
print( "Sleep in")
elif day == "Saturday":
print( "Do chores")
else:
print( "Go to work")Go to work
Note that ordinary data types have boolean values associated with them. Indeed, casting anything that has a 0 value (the integer or floating point 0, an empty string "", or an empty list []) to a boolean will return False:
bool(1)Truebool(0.0)Falsebool(["This "," is "," a "," list"])True1.8Code Example: The Fibonacci Sequence¶
The Fibonacci sequence is a sequence in math that starts with 0 and 1, and then each successive entry is the sum of the previous two. Thus, the sequence goes 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ...
A very common exercise in programming books is to compute the Fibonacci sequence up to some number n.
n = 10
sequence = [0, 1]
for i in range(2, n): # loop to generate the sequence
sequence.append(sequence[i - 1] + sequence[i - 2])
print(sequence)[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
Note that in Python # starts a comment.
1.9Functions¶
We might want to use the Fibonacci snippet with different sequence lengths. We could cut and paste the code into another cell, changing the value of n, but it’s easier and more useful to make a function out of the previous snippet code:
def fibonacci(sequence_length):
"Return the Fibonacci sequence of length *sequence_length*"
sequence = [0, 1]
if sequence_length < 1:
print("A Fibonacci sequence can be defined only for length 1 or greater")
return
if 0 < sequence_length < 3:
return sequence[:sequence_length]
for i in range(2,sequence_length):
sequence.append(sequence[i-1]+sequence[i-2])
return sequenceWe can now call fibonacci() for different sequence_lengths:
fibonacci(2)[0, 1]fibonacci(12)[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]We’ve introduced a several new features here. First, note that the function itself is defined as a code block (a colon followed by an indented block). This is the standard way that Python delimits things. Next, note that the first line of the function is a single string. This is called a docstring, and is a special kind of comment that is often available to people using the function through the python command line:
help(fibonacci)Help on function fibonacci in module __main__:
fibonacci(sequence_length)
Return the Fibonacci sequence of length *sequence_length*
If you define a docstring for all of your functions, it makes it easier for other people to use them, since they can get help on the arguments and return values of the function.
Note that I have also added some ifs to handle corner cases, and possibly issue a warning if the given length is not right.
1.10Recursion and Factorials¶
Functions can also call themselves, something that is often called recursion. We’re going to experiment with recursion by computing the factorial function. The factorial is defined for a positive integer n as
First, note that we don’t need to write a function at all, since this is a function built into the standard math library (math.factorial). However, for the sake of this example, we note that
and therefore we can define
def fact(n):
if n <= 0:
return 1
return n*fact(n-1)fact(100)93326215443944152681699238856266700490715968264381621468592963895217599993229915608941463976156518286253697920827223758251185210916864000000000000000000000000Recursion can be very elegant, and can lead to very simple programs, but can also lead to memory problems if the number of recursive calls is too large. By the way note that, contrary to C, Python has unbounded integers, so that there any integer can be represented. This means, of course, that the memory footprint of an integer depends on its value.
1.11Two more data structures¶
There are two more data structures that are very useful (and thus very common) in Python.
1.11.1Tuples¶
A tuple is a sequence object like a list or a string. It’s constructed by grouping a sequence of objects together with commas, either without brackets, or with parentheses:
t = (1, 2, 'hi', 9.0)
t(1, 2, 'hi', 9.0)Tuples are like lists, in that you can access the elements using indices:
t[1]2However, tuples are immutable objects: elements cannot be added or removed, or even modified:
t.append(7)---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[78], line 1
----> 1 t.append(7)
AttributeError: 'tuple' object has no attribute 'append't[1] = 77---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[79], line 1
----> 1 t[1] = 77
TypeError: 'tuple' object does not support item assignmentTuples are useful anytime you want to group different pieces of data together in an object. Note that immutability in many cases is an excellent attribute, since it ensures that the resulting sequence will not be changed ever in the code.
Tuples can be used when functions return more than one value. Say we wanted to compute the smallest x- and y-coordinates of out of a list. We could write:
positions = [
('Bob', 0.0, 21.0),
('Cat', 2.5, 13.1),
('Dog', 33.0, 1.2)
]
def minmax(objects):
minx = 1e20 # These are set to really big numbers
miny = 1e20
for obj in objects:
name, x, y = obj
if x < minx:
minx = x
if y < miny:
miny = y
return minx, miny
x, y = minmax(positions)
print(x, y)0.0 1.2
Here we did two things with tuples you haven’t seen before. First, we unpacked an object into a set of named variables using tuple assignment, which is very handy:
name, x, y = objWe also returned multiple values (minx, miny), which were then assigned to two other variables (x, y), again by tuple assignment. Try writing something like this in C!
A rather common use for tuple assignment is to swap variables:
x, y = 1,2
y, x = x, y
print(x, y)2 1
1.11.2Dictionaries¶
A dictionary is an object that is often called “map” or “associative array” in other languages. Whereas a list associates an integer index with value, a dictionary associates a key to a value, where the key can be of (almost) any type. Whereas lists are formed with square brackets, [], dictionaries use curly brackets, {}:
ages = {"Rick": 58, "Bob": 86, "Fred": 21}
print("Rick's age is ", ages["Rick"])Rick's age is 58
There’s also a convenient way to create dictionaries without having to quote the keys.
Note that the len() command works on both tuples and dictionaries:
len(t)3len(ages)31.12Plotting with Matplotlib¶
We can generally understand trends in data by using a plotting program to chart it. Python has a wonderful plotting library called Matplotlib.
As an example, we have looked at two different functions, the Fibonacci function, and the factorial function, both of which grow faster than polynomially. Which one grows the fastest? Let’s plot them. First, we generate the Fibonacci sequence of length 20:
fibs = fibonacci(10)Next we generate the corresponding list of factorials:
facts = []
for i in range(10):
facts.append(fact(i))Then we import the library:
import matplotlib.pyplot as pltTo make the code work in Jupyter notebooks, you may also have to include the command:
%matplotlib inlineNow we can plot the two sequences by using matplotlib’s plot function:
plt.plot(facts, label="factorial")
plt.plot(fibs, label="Fibonacci")
plt.xlabel("n")
plt.ylabel("Value")
plt.legend()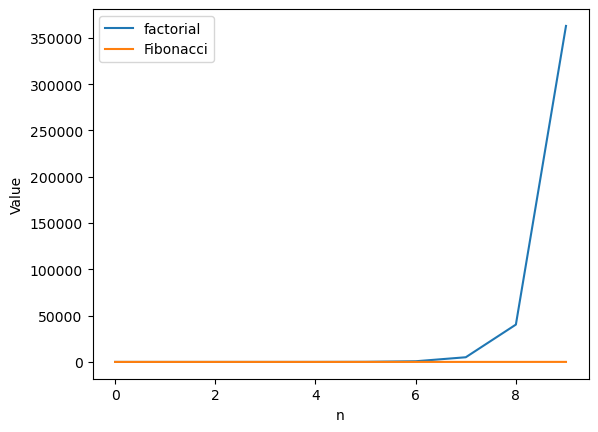
The factorial function grows much faster. In fact, you can’t even see the Fibonacci sequence. It’s not entirely surprising: a function where we multiply by n each iteration is bound to grow faster than one where we add (roughly) n each iteration.
Let’s plot these on a semilog plot so we can see them both a little more clearly:
plt.plot(facts,label="factorial")
plt.plot(fibs,label="Fibonacci")
plt.yscale("log")
plt.xlabel("n")
plt.ylabel("Value")
plt.legend()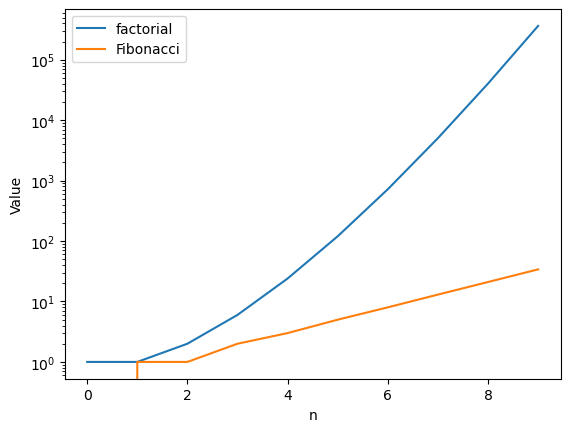
2Numpy and Scipy¶
Numpy contains core routines for doing fast vector, matrix, and linear algebra-type operations in Python. Scipy contains additional routines for optimization, special functions, and so on. Both contain modules written in C and Fortran to improve the performance.
First of all, we import numpy with
import numpy as np2.1Making vectors and matrices¶
Fundamental to both Numpy and Scipy is the ability to work with vectors, matrices or their generalisations, tensors. You can create arrays from lists using the np.array() function:
np.array([1, 2, 3, 4, 5, 6])array([1, 2, 3, 4, 5, 6])You can optionally pass in a second argument to np.array to choose a numeric type. There are a number of types listed here that your array can be, comprising integer (int, np.uint8 or np.int64, for instance) and floating point (e.g. float, np.float32 or np.complex64) types.
np.array([1, 2, 3, 4, 5, 6], dtype=np.int64)array([1, 2, 3, 4, 5, 6])np.array([1, 2, 3, 4, 5, 6], np.complex128)array([1.+0.j, 2.+0.j, 3.+0.j, 4.+0.j, 5.+0.j, 6.+0.j])To build multidimensional arrays (such as matrices), you can use the array command with lists of lists:
np.array([[0, 1],[1, 0]], dtype=float)array([[0., 1.],
[1., 0.]])You can also define arrays of arbitrary shape using the zeros command:
np.zeros((3, 3), dtype=float)array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])where the first argument is a tuple containing the shape of the array, and the second is the data type argument, which follows the same conventions as in the array command.
Note that you can define either row or column vectors:
row_v = np.zeros(3, dtype=float) # using (1, 3) instead of 3 would yield the same result
print("Row vector:", row_v)
col_v = np.zeros((3, 1), dtype=float)
print("Column vector:\n", col_v)Row vector: [0. 0. 0.]
Column vector:
[[0.]
[0.]
[0.]]
There’s also an identity command that behaves as you’d expect:
np.identity(4, dtype=float)array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])as well as a ones() function.
2.2Linspace, matrix functions, and plotting¶
The linspace command makes a linear array of a specified number of points from a starting to an ending value:
np.linspace(0, 1, 10)array([0. , 0.11111111, 0.22222222, 0.33333333, 0.44444444,
0.55555556, 0.66666667, 0.77777778, 0.88888889, 1. ])The optional third argument is the number of points, which defaults to 50.
np.linspace(0, 1, 11)array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ])linspace() is an easy way to make coordinates for plotting. Functions in the numpy library can act on an entire vector (or even a matrix) of points at once. Thus,
x = np.linspace(0, 2 * np.pi)
np.sin(x)array([ 0.00000000e+00, 1.27877162e-01, 2.53654584e-01, 3.75267005e-01,
4.90717552e-01, 5.98110530e-01, 6.95682551e-01, 7.81831482e-01,
8.55142763e-01, 9.14412623e-01, 9.58667853e-01, 9.87181783e-01,
9.99486216e-01, 9.95379113e-01, 9.74927912e-01, 9.38468422e-01,
8.86599306e-01, 8.20172255e-01, 7.40277997e-01, 6.48228395e-01,
5.45534901e-01, 4.33883739e-01, 3.15108218e-01, 1.91158629e-01,
6.40702200e-02, -6.40702200e-02, -1.91158629e-01, -3.15108218e-01,
-4.33883739e-01, -5.45534901e-01, -6.48228395e-01, -7.40277997e-01,
-8.20172255e-01, -8.86599306e-01, -9.38468422e-01, -9.74927912e-01,
-9.95379113e-01, -9.99486216e-01, -9.87181783e-01, -9.58667853e-01,
-9.14412623e-01, -8.55142763e-01, -7.81831482e-01, -6.95682551e-01,
-5.98110530e-01, -4.90717552e-01, -3.75267005e-01, -2.53654584e-01,
-1.27877162e-01, -2.44929360e-16])Note here that we used the numpy (and not the math) version of the sin function, which can take a vector of points. We also used the value of built into the numpy library. This is a nice “recipe” to plot functions with matplotlib:
plt.plot(x, np.sin(x))
2.3Matrix operations¶
Matrix objects act sensibly when multiplied by scalars:
0.125 * np.identity(3, dtype=float)array([[0.125, 0. , 0. ],
[0. , 0.125, 0. ],
[0. , 0. , 0.125]])Same-shape matrices can be added together:
np.identity(2, dtype=float) + np.array([[1, 1], [1, 2]])array([[2., 1.],
[1., 3.]])Note that the * operator acts in an element-wise way:
np.identity(2) * np.ones((2,2))array([[1., 0.],
[0., 1.]])To get matrix multiplication, you use the @ operator:
np.identity(2) @ np.ones((2, 2))array([[1., 1.],
[1., 1.]])There are determinant(), inverse(), and transpose() functions that act as you would suppose. Transpose can be abbreviated with .T at the end of a matrix object:
m = np.array([[1,2],[3,4]])
m.Tarray([[1, 3],
[2, 4]])2.4Matrix Solvers¶
You can solve systems of linear equations using the np.linalg.solve() function:
A = np.array([[1, 1, 1], [0, 2, 5], [2, 5, -1]]) # matrix
b = np.array([6, -4, 27]) # coefficients
np.linalg.solve(A, b)array([ 5., 3., -2.])There are also a number of routines to compute eigenvalues and eigenvectors that can be useful for scientific computing:
eigvals()returns the eigenvalues of a matrixeigvalsh()returns the eigenvalues of a Hermitian matrixeig()returns the eigenvalues and eigenvectors of a matrixeigh()returns the eigenvalues and eigenvectors of a Hermitian matrix.
A = np.array([[13, -4],[-4, 7]],'d')
np.linalg.eigvalsh(A)array([ 5., 15.])np.linalg.eigh(A)EighResult(eigenvalues=array([ 5., 15.]), eigenvectors=array([[-0.4472136 , -0.89442719],
[-0.89442719, 0.4472136 ]]))def nderiv(y, x):
"Finite difference derivative of the function f"
n = len(y)
d = np.zeros(n, dtype=float) # assume double
# Use centered differences for the interior points, one-sided differences for the ends
for i in range(1,n-1):
d[i] = (y[i+1]-y[i-1])/(x[i+1]-x[i-1])
d[0] = (y[1]-y[0])/(x[1]-x[0])
d[n-1] = (y[n-1]-y[n-2])/(x[n-1]-x[n-2])
return dWe know that the derivative of the sin function is the cos function. Let’s see whether this is the case using the numeric derivative:
x = np.linspace(0,2*np.pi)
dsin = nderiv(np.sin(x),x)
plt.plot(x, dsin, label='numerical')
plt.plot(x, np.cos(x), label='analytical')
plt.title("Comparison of numerical and analytical derivatives of sin(x)")
plt.legend()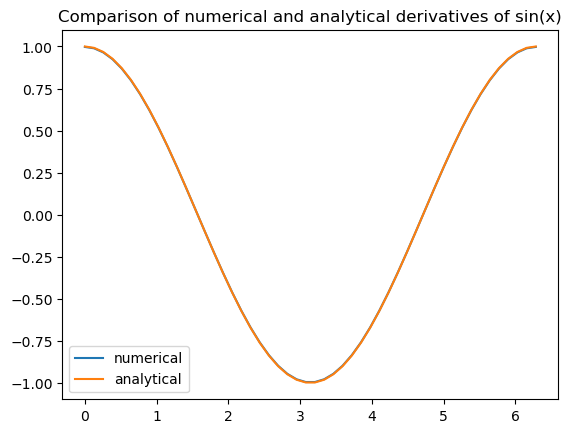
Pretty close!
2.5Monte Carlo, random numbers, and computing ¶
Many methods in scientific computing rely on Monte Carlo integration, where a sequence of (pseudo) random numbers are used to approximate the integral of a function. Python has good random number generators in the standard library. The random() function gives pseudorandom numbers uniformly distributed between 0 and 1:
from random import random
rands = []
for i in range(100):
rands.append(random())
plt.plot(rands)
Note that random() uses the Mersenne Twister algorithm, which is more sophisticated (and has better statistical properties) than the linear congruential generator that C uses by default. There are also functions to generate random integers, to randomly shuffle a list, and functions to pick random numbers from a particular distribution, like the normal distribution:
from random import gauss
grands = []
for i in range(100):
grands.append(gauss(0,1))
plt.plot(grands)
It is generally more efficient to generate a list of random numbers all at once, particularly if you’re drawing from a non-uniform distribution. Numpy has functions to generate vectors and matrices of particular types of random distributions.
plt.plot(np.random.rand(100))
As an example, consider the following snippet, which estimates the value of by taking random numbers as and coordinates, and counting how many of them are in the unit circle:
npts = 5000
xs = 2 * np.random.rand(npts) - 1
ys = 2 * np.random.rand(npts) - 1
r2 = xs**2 + ys**2
ninside = (r2 < 1).sum()
plt.title("Approximation to pi = %f" % (4 * ninside / npts))
plt.gca().set_aspect('equal', adjustable='box') # makes the two axes equally long so that the plot is a perfect square
plt.plot(xs[r2 < 1],ys[r2 < 1],'b.')
plt.plot(xs[r2 > 1],ys[r2 > 1],'r.')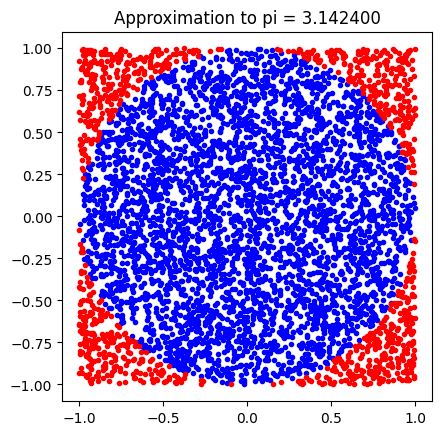
2.6Numerical Integration¶
Integration can be hard, and sometimes it’s easier to work out a definite integral using an approximation. For example, suppose we wanted to figure out the integral:
def f(x):
return np.exp(-x)
x = np.linspace(0,10)
plt.plot(x,np.exp(-x))
Scipy has a numerical integration routine quad() (since sometimes numerical integration is called quadrature) that we can use for this:
from scipy.integrate import quad
quad(f, 0, np.inf)(1.0000000000000002, 5.842606742906004e-11)There are also 2d and 3d numerical integrators in Scipy. See the docs for more information.
3Intermediate Python¶
Consider the following (long) string:
myoutput = """\
@ Step Energy Delta E Gmax Grms Xrms Xmax Walltime
@ ---- ---------------- -------- -------- -------- -------- -------- --------
@ 0 -6095.12544083 0.0D+00 0.03686 0.00936 0.00000 0.00000 1391.5
@ 1 -6095.25762870 -1.3D-01 0.00732 0.00168 0.32456 0.84140 10468.0
@ 2 -6095.26325979 -5.6D-03 0.00233 0.00056 0.06294 0.14009 11963.5
@ 3 -6095.26428124 -1.0D-03 0.00109 0.00024 0.03245 0.10269 13331.9
@ 4 -6095.26463203 -3.5D-04 0.00057 0.00013 0.02737 0.09112 14710.8
@ 5 -6095.26477615 -1.4D-04 0.00043 0.00009 0.02259 0.08615 20211.1
@ 6 -6095.26482624 -5.0D-05 0.00015 0.00002 0.00831 0.03147 21726.1
@ 7 -6095.26483584 -9.6D-06 0.00021 0.00004 0.01473 0.05265 24890.5
@ 8 -6095.26484405 -8.2D-06 0.00005 0.00001 0.00555 0.01929 26448.7
@ 9 -6095.26484599 -1.9D-06 0.00003 0.00001 0.00164 0.00564 27258.1
@ 10 -6095.26484676 -7.7D-07 0.00003 0.00001 0.00161 0.00553 28155.3
@ 11 -6095.26484693 -1.8D-07 0.00002 0.00000 0.00054 0.00151 28981.7
@ 11 -6095.26484693 -1.8D-07 0.00002 0.00000 0.00054 0.00151 28981.7"""First, note that the data is entered into a multi-line string. When Python sees three quote marks """ or ''' it treats everything following as part of a single string, including newlines, tabs, and anything else, until it sees the same three quote marks (""" has to be followed by another """, and ''' has to be followed by another ''') again.
We start by splitting this big string into a list of strings, since each line corresponds to a separate piece of data. We use split("\n"), which breaks a string into a new element every time it sees a newline (`\n) character:
lines = myoutput.split("\n")
lines['@ Step Energy Delta E Gmax Grms Xrms Xmax Walltime',
'@ ---- ---------------- -------- -------- -------- -------- -------- --------',
'@ 0 -6095.12544083 0.0D+00 0.03686 0.00936 0.00000 0.00000 1391.5',
'@ 1 -6095.25762870 -1.3D-01 0.00732 0.00168 0.32456 0.84140 10468.0',
'@ 2 -6095.26325979 -5.6D-03 0.00233 0.00056 0.06294 0.14009 11963.5',
'@ 3 -6095.26428124 -1.0D-03 0.00109 0.00024 0.03245 0.10269 13331.9',
'@ 4 -6095.26463203 -3.5D-04 0.00057 0.00013 0.02737 0.09112 14710.8',
'@ 5 -6095.26477615 -1.4D-04 0.00043 0.00009 0.02259 0.08615 20211.1',
'@ 6 -6095.26482624 -5.0D-05 0.00015 0.00002 0.00831 0.03147 21726.1',
'@ 7 -6095.26483584 -9.6D-06 0.00021 0.00004 0.01473 0.05265 24890.5',
'@ 8 -6095.26484405 -8.2D-06 0.00005 0.00001 0.00555 0.01929 26448.7',
'@ 9 -6095.26484599 -1.9D-06 0.00003 0.00001 0.00164 0.00564 27258.1',
'@ 10 -6095.26484676 -7.7D-07 0.00003 0.00001 0.00161 0.00553 28155.3',
'@ 11 -6095.26484693 -1.8D-07 0.00002 0.00000 0.00054 0.00151 28981.7',
'@ 11 -6095.26484693 -1.8D-07 0.00002 0.00000 0.00054 0.00151 28981.7']We now want to do three things:
Skip over the lines that don’t carry any information
Break apart each line that does carry information and grab the pieces we want
Turn the resulting data into something that we can plot.
For this data, we really only want the Energy column, the Gmax column (which contains the maximum gradient at each step), and perhaps the Walltime column.
Since the data is now in a list of lines, we can iterate over it:
for line in lines[2:]:
# do something with each line
words = line.split()Let’s examine what we just did: first, we used a for loop to iterate over each line. However, we skipped the first two, sincelines[2:] only takes the lines starting from index 2, since lines[0] contained the title information, and lines[1] contained underscores.
We then split each line into chunks (which we’re calling “words”, even though in most cases they’re numbers) using the string split() function on a string. If called without arguments, split() will split a string every time a whitespace is encountered:
lines[2].split()['@',
'0',
'-6095.12544083',
'0.0D+00',
'0.03686',
'0.00936',
'0.00000',
'0.00000',
'1391.5']This is almost exactly what we want. Now we can get the columns that we want:
for line in lines[2:]:
# do something with each line
words = line.split()
energy = words[2]
gmax = words[4]
time = words[8]
print(energy,gmax,time)-6095.12544083 0.03686 1391.5
-6095.25762870 0.00732 10468.0
-6095.26325979 0.00233 11963.5
-6095.26428124 0.00109 13331.9
-6095.26463203 0.00057 14710.8
-6095.26477615 0.00043 20211.1
-6095.26482624 0.00015 21726.1
-6095.26483584 0.00021 24890.5
-6095.26484405 0.00005 26448.7
-6095.26484599 0.00003 27258.1
-6095.26484676 0.00003 28155.3
-6095.26484693 0.00002 28981.7
-6095.26484693 0.00002 28981.7
This is fine for printing things out, but if we want to do something with the data, either make a calculation with it or pass it into a plotting, we need to convert the strings into regular floating point numbers. We can use the float() function for this. We also need to save it in some form. I’ll do this as follows:
data = []
for line in lines[2:]:
# do something with each line
words = line.split()
energy = float(words[2])
gmax = float(words[4])
time = float(words[8])
data.append((energy,gmax,time))
data = np.array(data)We now have our data in a numpy array, so we can choose columns to print. With numpy matrices, multidimensional arrays can be accessed by using “slice tuples”. For instance, if we want the first column of a matrix such as data, we can use data[:,0]:
plt.plot(data[:,0])
plt.xlabel('step')
plt.ylabel('Energy [a.u.]')
plt.title('Energy convergence')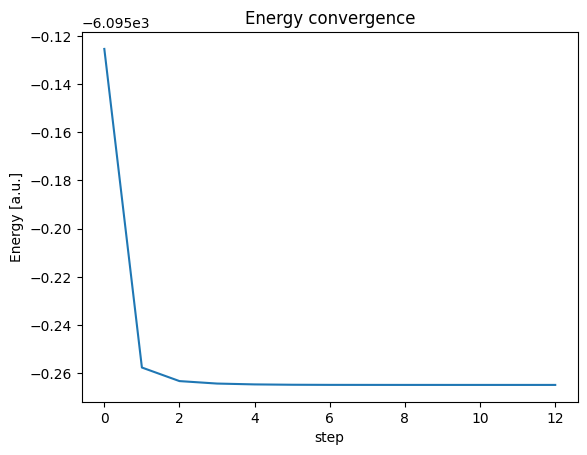
3.1More Sophisticated String Formatting and Processing¶
Strings are a big deal in most modern languages, and hopefully the previous sections helped underscore how versatile Python’s string processing techniques are. We will continue this topic in this chapter.
We can print out lines in Python using the print command.
print("I have 3 errands to run")I have 3 errands to run
In Jupyter notebooks we don’t even need the print command, since it will display the last expression not assigned to a variable.
"I have 3 errands to run"'I have 3 errands to run'print() even converts some arguments to strings for us:
a, b, c = 1, 2, 3
print("The variables are ", 1, 2, 3)The variables are 1 2 3
As versatile as this is, you typically need more freedom over the data you print out. For example, what if we want to print a bunch of data to exactly 4 decimal places? We can do this using formatted strings.
Formatted strings share a syntax with the C printf statement. We make a string that has some funny format characters in it, and then pass a bunch of variables into the string that fill out those characters in different ways.
For example,
print("Pi as a decimal = %d" % np.pi)
print("Pi as a float = %f" % np.pi)
print("Pi with 4 decimal places = %.4f" % np.pi)
print("Pi with overall fixed length of 10 spaces, with 6 decimal places = %10.6f" % np.pi)
print("Pi as in exponential format = %e" % np.pi)Pi as a decimal = 3
Pi as a float = 3.141593
Pi with 4 decimal places = 3.1416
Pi with overall fixed length of 10 spaces, with 6 decimal places = 3.141593
Pi as in exponential format = 3.141593e+00
The other use of the percent sign is after the string, to pipe a set of variables in. You can pass in multiple variables (if your formatting string supports it) by putting a tuple after the percent. Thus,
print("The variables specified earlier are %d, %d, and %d" % (a,b,c))The variables specified earlier are 1, 2, and 3
3.2Optional arguments¶
You will recall that the linspace() function can take either two arguments (for the starting and ending points):
np.linspace(0, 1)array([0. , 0.02040816, 0.04081633, 0.06122449, 0.08163265,
0.10204082, 0.12244898, 0.14285714, 0.16326531, 0.18367347,
0.20408163, 0.2244898 , 0.24489796, 0.26530612, 0.28571429,
0.30612245, 0.32653061, 0.34693878, 0.36734694, 0.3877551 ,
0.40816327, 0.42857143, 0.44897959, 0.46938776, 0.48979592,
0.51020408, 0.53061224, 0.55102041, 0.57142857, 0.59183673,
0.6122449 , 0.63265306, 0.65306122, 0.67346939, 0.69387755,
0.71428571, 0.73469388, 0.75510204, 0.7755102 , 0.79591837,
0.81632653, 0.83673469, 0.85714286, 0.87755102, 0.89795918,
0.91836735, 0.93877551, 0.95918367, 0.97959184, 1. ])or it can take three arguments, for the starting point, the ending point, and the number of points:
np.linspace(0, 1, 5)array([0. , 0.25, 0.5 , 0.75, 1. ])You can also pass in keywords to exclude the endpoint:
np.linspace(0, 1, 5, endpoint=False)array([0. , 0.2, 0.4, 0.6, 0.8])Right now, we only know how to specify functions that have a fixed number of arguments. We’ll learn how to do the more general cases here.
If we’re defining a simple version of linspace, we would start with:
def my_linspace(start, end):
npoints = 5
v = []
d = (end - start) / float(npoints - 1)
for i in range(npoints):
v.append(start + i * d)
return v
my_linspace(0, 1)[0.0, 0.25, 0.5, 0.75, 1.0]We can add an optional argument by specifying a default value in the argument list:
def my_linspace(start, end, npoints=5):
v = []
d = (end - start) / float(npoints - 1)
for i in range(npoints):
v.append(start + i * d)
return vThis gives exactly the same result if we don’t specify anything:
my_linspace(0, 1)[0.0, 0.25, 0.5, 0.75, 1.0]But also let’s us override the default value with a third argument:
my_linspace(0, 1, 10)[0.0,
0.1111111111111111,
0.2222222222222222,
0.3333333333333333,
0.4444444444444444,
0.5555555555555556,
0.6666666666666666,
0.7777777777777777,
0.8888888888888888,
1.0]We can add arbitrary keyword arguments to the function definition by putting a keyword argument **kwargs handle in:
def my_linspace(start, end, npoints=5, **kwargs):
endpoint = kwargs.get('endpoint', True)
v = []
if endpoint:
d = (end - start) / float(npoints - 1)
else:
d = (end - start) / float(npoints)
for i in range(npoints):
v.append(start + i * d)
return v
my_linspace(0, 1, 10, endpoint=False)[0.0,
0.1,
0.2,
0.30000000000000004,
0.4,
0.5,
0.6000000000000001,
0.7000000000000001,
0.8,
0.9]What the keyword argument construction does is to take any additional keyword arguments (i.e. arguments specified by name, like endpoint=False), and stick them into a dictionary called kwargs (you can call it anything you like, but it has to be preceded by two stars). You can then grab items out of the dictionary using the get command, which also lets you specify a default value. I realize it takes a little getting used to, but it is a common construction in Python code, and you should be able to recognize it.
3.3List Comprehensions and Generators¶
List comprehensions are a streamlined way to make lists. They look something like a list definition, with some logic thrown in. For example:
odds = [2 * i + 1 for i in range(10)]
print(odds)[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
You can also put some boolean testing into the construct:
odds = [i for i in range(20) if i % 2 == 1]
print(odds)[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
from operator import add, mul
add(1, 2)3mul(3, 4)12These are useful building blocks for functional programming.
The lambda operator allows us to build anonymous functions, which are simply functions that aren’t defined by a normal def statement with a name. For example, a function that doubles the input is:
def doubler(x): return 2*x
doubler(17)34We could also write this as:
lambda x: 2*x<function __main__.<lambda>(x)>And assign it to a function separately:
another_doubler = lambda x: 2*x
another_doubler(19)38lambda is particularly convenient (as we’ll see below) in passing simple functions as arguments to other functions.
map is a way to repeatedly apply a function to a list:
list(map(float,'1 2 3 4 5'.split()))[1.0, 2.0, 3.0, 4.0, 5.0]reduce is a way to repeatedly apply a function to the first two items of the list. There already is a sum function in Python that is a reduction:
sum([1, 2, 3, 4, 5])15We can use reduce to define an analogous prod function:
from functools import reduce
def prod(l):
return reduce(mul, l)
prod([1, 2, 3, 4, 5])1203.4Object Oriented Programming¶
We’ve seen a lot of examples of objects in Python. We create a string object with quote marks:
mystring = "Hi there"and we have a bunch of methods we can use on the object:
mystring.split()['Hi', 'there']mystring.startswith('Hi')Truelen(mystring)8Object oriented programming simply gives you the tools to define objects and methods for yourself. It’s useful anytime you want to keep some data (like the characters in the string) tightly coupled to the functions that act on the data (length, split, startswith, etc.).
As an example, we can write a very primitive immutable 3D vector:
class Vector:
"""
Vector: a terrible 3D vector
"""
def __init__(self, x, y, z):
self._coords = np.array([x, y, z], dtype=float)
def x(self):
return self._coords[0]
def y(self):
return self._coords[1]
def z(self):
return self._coords[2]
def dot(self, w):
return np.dot(self._coords, w._coords)
def __add__(self, other):
return self._coords + other._coords
def __sub__(self, other):
return self._coords - other._coordsThe __init__() function specifies the operations to perform when the object is created. The self argument is the object itself, and we don’t pass it in. Note that we define some functions to access the three coordinates, as well as a function to compute the dot product.
Finally, we “overload” two operators, + and -. The class can be used like this:
a = Vector(1, 0, 0)
b = Vector(0, 1, 0)
print(a.dot(b))
print(a + b)
print(a - b)0.0
[1. 1. 0.]
[ 1. -1. 0.]